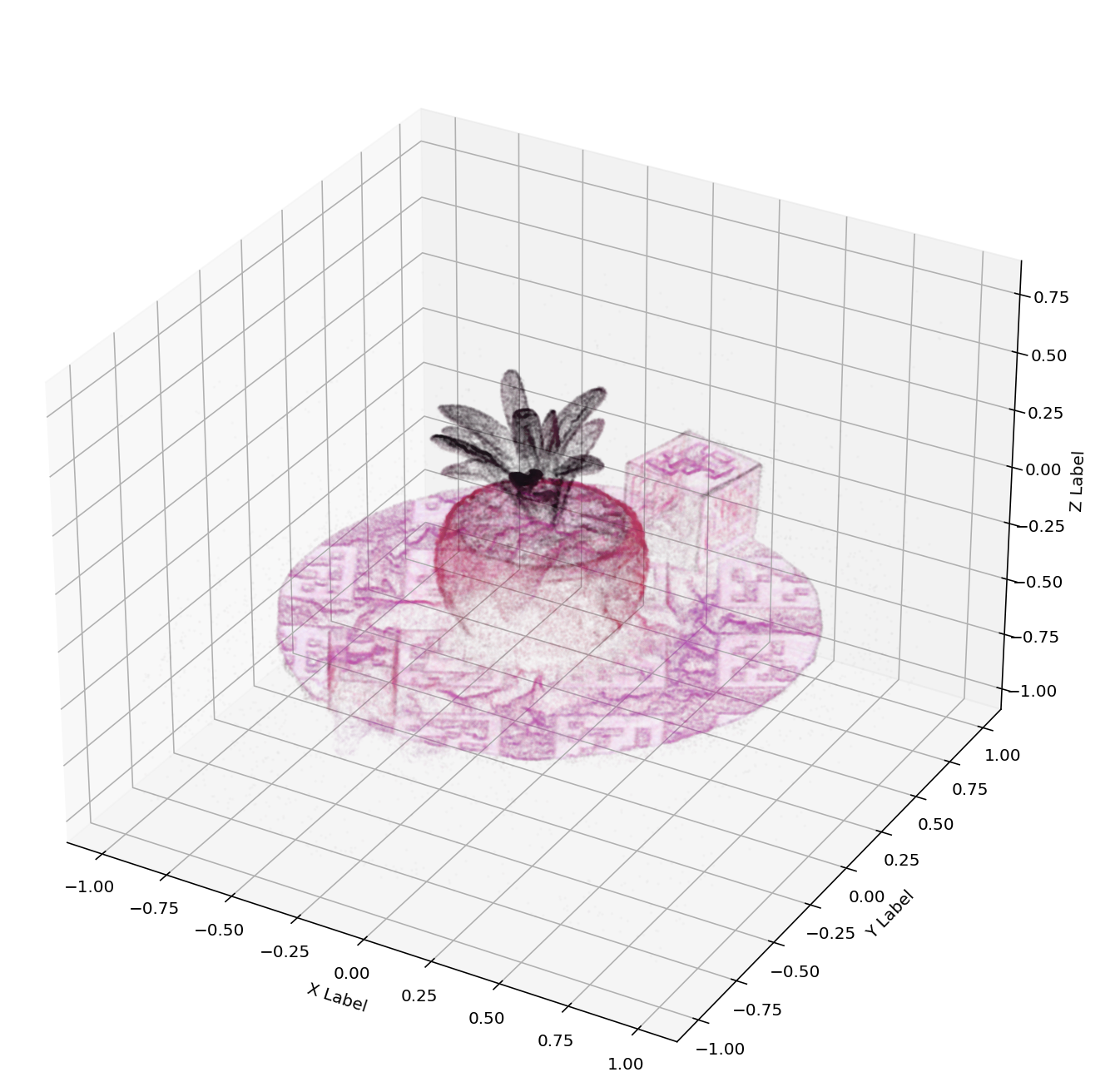
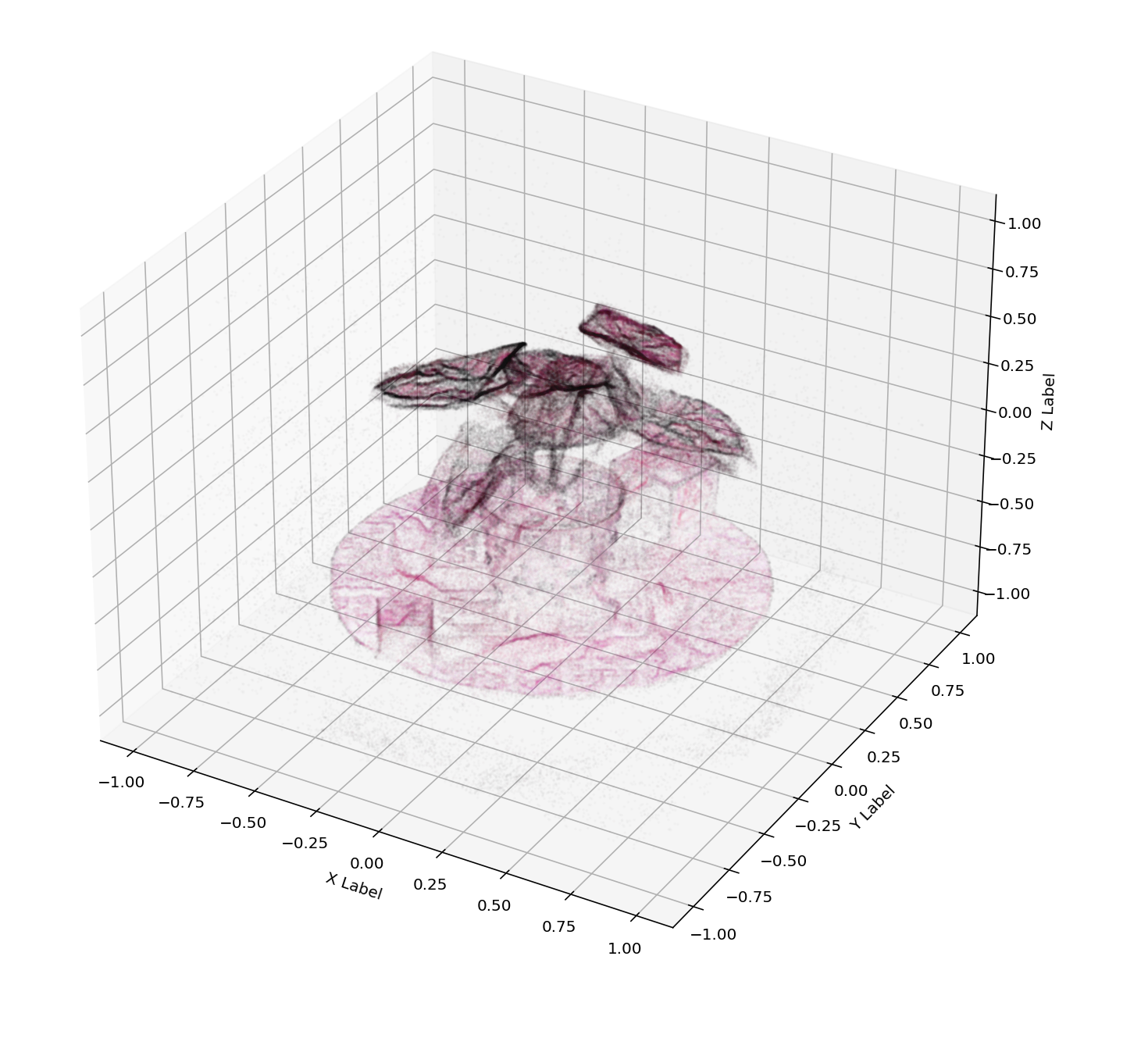
Abstract
Hyperspectral Imagery (HSI) has been used in many applications to non-destructively determine the material and/or chemical compositions of samples. There is growing interest in creating 3D hyperspectral reconstructions, which could provide both spatial and spectral information while also mitigating common HSI challenges such as non-Lambertian surfaces and translucent objects. However, traditional 3D reconstruction with HSI is difficult due to technological limitations of hyperspectral cameras. In recent years, Neural Radiance Fields (NeRFs) have seen widespread success in creating high quality volumetric 3D representations of scenes captured by a variety of camera models. Leveraging recent advances in NeRFs, we propose computing a hyperspectral 3D reconstruction in which every point in space and view direction is characterized by wavelength-dependent radiance and transmittance spectra. To evaluate our approach, a dataset containing nearly 2000 hyperspectral images across 8 scenes and 2 cameras was collected. We perform comparisons against traditional RGB NeRF baselines and apply ablation testing with alternative spectra representations. Finally, we demonstrate the potential of hyperspectral NeRFs for hyperspectral super-resolution and imaging sensor simulation. We show that our hyperspectral NeRF approach enables creating fast, accurate volumetric 3D hyperspectral scenes and enables several new applications and areas for future study.